Some time ago, I was engaged in a discussion with one of our customers to investigate the possibility of VMware Site Recovery Manager implementation in their datacenter. The discussion turned technical pretty soon and when I asked what their RPO or RTO requirements were, they could not answer it straight away simply because they didn’t know what it was or what it meant. And when I mentioned WRT and MTD, they were stunned even more. So to clarify it a little bit for them I started drawing and explaining the following along the way.
Consider the following scenario.
Stage 1: Business as usual

At this stage all systems are running production and working correctly.
Stage 2: Disaster occurs
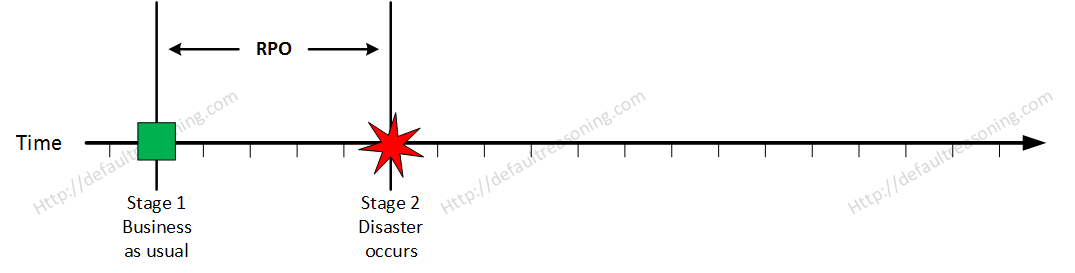
On a given point in time, disaster occurs and systems needs to be recovered. At this point the Recovery Point Objective (RPO) determines the maximum acceptable amount of data loss measured in time. For example, the maximum tolerable data loss is 15 minutes.
Stage 3: Recovery
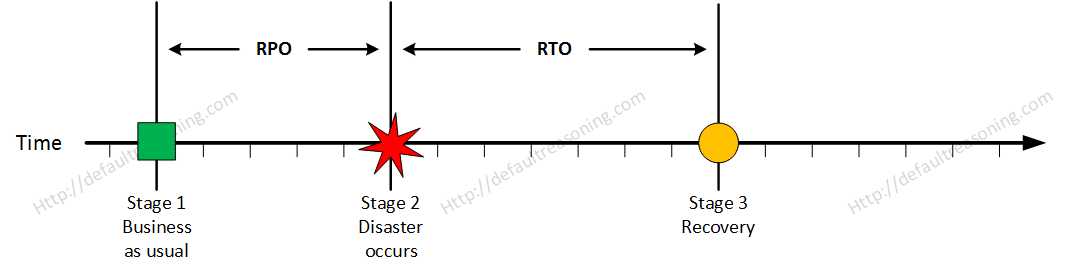
At this stage the system are recovered and back online but not ready for production yet. The Recovery Time Objective (RTO) determines the maximum tolerable amount of time needed to bring all critical systems back online. This covers, for example, restore data from back-up or fix of a failure. In most cases this part is carried out by system administrator, network administrator, storage administrator etc.
Stage 4: Resume Production
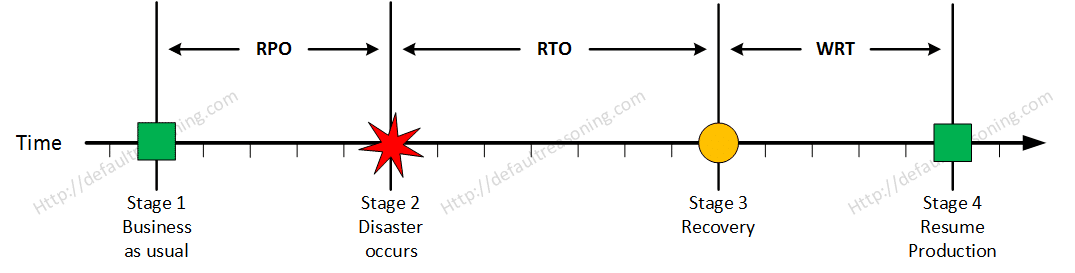
At this stage all systems are recovered, integrity of the system or data is verified and all critical systems can resume normal operations. The Work Recovery Time (WRT) determines the maximum tolerable amount of time that is needed to verify the system and/or data integrity. This could be, for example, checking the databases and logs, making sure the applications or services are running and are available. In most cases those tasks are performed by application administrator, database administrator etc. When all systems affected by the disaster are verified and/or recovered, the environment is ready to resume the production again.
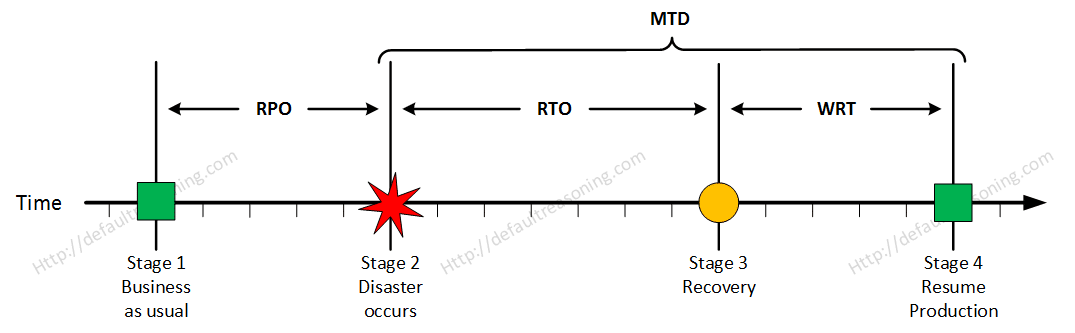
The sum of RTO and WRT is defined as the Maximum Tolerable Downtime (MTD) which defines the total amount of time that a business process can be disrupted without causing any unacceptable consequences. This value should be defined by the business management team or someone like CTO, CIO or IT manager.
This is of course a simple example of a Business Continuity/Disaster Recovery plan and should be included in your Business Impact Analysis (BIA).
I hope this short explanation gives you some starting points when discussing a Business Continuity/Disaster Recovery implementation with your customer.
Cheers!
– Marek.Z
It seems there is a typo in third last paragraph,”The sum of RTO and PRO” I think you meant “The sum of RTO and WRT”?
Thanks for the nice graphical explanation.
Hi Obaid,
Yes, indeed. Thank you for pointing it out.
Cheers!
Thank you Marek. Great explanation and easy to understand.
Excellent illustration, thank you!
Great post!
I just wonder why you use ‘Business as usual’ instead of ‘Backup as usual or Last Valid Backup’ ? IMHO it will be more accurate.
KB
Thanks
I assume your backup strategy is already in place and you are able to recover from backup based on your company requirements. Besides, backup is out of scope in this blog post. I just wanted to explain what the acronyms mean.
Cheers!
Great writeup!
So MTD is same as MTO? Just a different terminology or they do have a difference ?
Just as depicted, MTD = RTO + WRT.
Don’t know about MTO abbreviation though…
Nice article.. But I still have a doubt about relation between BIA, RTO and MTD.
MTD will be input to BIA or vice versa.Kindly clarify
Thanks
Mohammed Arif
So, basically, you got your BIA for your entire corporation. Not just your IT infra and this article was written based on my consulting job for a few customers.
Hope this helps.
Thanks a lot Marek.
Now:) i understood the entire concept .
Cheers! 🙂
Studying for my CompTIA Advanced Security Professional (CASP) exam – this really helped, thank you
Thanks! Good luck on the exam!
Cheers!
What about the “think time” to decide if you want to invoke your recovery or attempt to repair the application without invoking? I don’t see this represented here. In the case where the invocation of recovery could result in a loss of data or risk of further issues, you want to be 100% sure you need to invoke before you do it. This increases the MTD.
Hi,
I assumed that the decision for recovery already has bee made and this blogs simply explains the steps that usually are performed during the recover. This of course can be tweaked to suite you environment.
Cheers!
Thanks for the explanation. The graphics helped clarify it better.
It’s a wonder why the textbook I’m reading doesn’t employ a graphical explanation such as this one. Thank you!
First, let me say that this is a great explanation of the terms.
Regarding Leon Funnell’s comment above, I personally have found that the clock for RTO does not start ticking until the decision to declare a disaster has been made. I always include that as a step in my process. That makes it clear to management that the decision to declare is a very important step; and the longer it takes to decide to declare, the longer critical systems remain down.
Good point.
Imo this really comes down to your approach to BC/DR for your organisation.
Cheers!
Very pertinent and critical point Taylor , declaring a crisis remain the C-suite responsibility .
In our organisation MDT is distinct and separate from RTO. MDT is RTO + think time (nominally 1 hour). This is because unless you have automated and loss-less DR, the decision point must be taken as recovery to DR is not your only option. Reboots, reconfiguration, troubleshooting are usually first steps.
Hi sir, from your point of view, in order to determine RTO for certain process key (note that this is business process, not RTO for IT), do I need to consider WRT as part or RTO?
Hi Fara,
Well, it depends. Is the process operational? Or do you need to perform additional steps to get it operational again.
Cheers!
Simple,effective representation and explanation of the acronyms, which makes it very to understand and grasp the concepts. As Jason said,many a text book lack this sort of representation. Thanks for the effort and explanation Marek. Helped me in getting clarity.
Regards,
Sebastian
Thanx so much this article is great,am studying for my CISSP it clarified a lot of things in a very simple manner…however is Maximum Allowable Downtime(MAD) and Maximum Tolerable Downtime(MTD) the same thing
Hi,
I am not sure. I didn’t see the MAD before but judging from the name, I think this could be the same thing.
Normally they are not.
MAD can be e.g. a legally mandated requirement while MTD can be an internal company target. When you have defined both, MTD would be shorter or same as MAD.
In the IAAS world, to make it worse, the customer would rarely share true MAD as it can be of a highly confidential nature and ask the vendor to treat MTD as “MAD”. This can create further complexity by obfuscation for the guy asked to solution it. But hey, life is complex.
Alright, cool. Thanks for sharing.
Hi Marek, what an article indeed..
I have a small query.. RTO is normally provided by the business if I am not wrong. So, from IT point of view, we will need WRT that is the “time to be taken by IT”. For wxample, Supply chain wants their applications back up in 1 hour, IT will say that we will need 30 Min more time (WRT) to verify the integrity and blah blah.. Hence MTD will become 90 min. The business will start shouting that we gave 60 min RTO and you are taking 90 min… Kindly guide..
Hi Umair,
Well, in most cases, yes. RTO is usually stated by the business as they have to decide what is tolerable. It is a business decision.
From IT point of view, during the RTO period, you restore your systems to the up-and-running state. After that you need to verify the integrity of the data (WRT) thus, as you describe, the MTD will become your 90 minutes. So, in fact, the IT needs 90 minutes to go back to the production state. But it really depends on your organisations’ procedures and requirements but also on IT staff that is involved with the recovery.
Hope this helps.
Cheers!
Thanks for the write up … Nicely documented.
It is an excellent explanation of the key words. Thank you.
Happy Morning Marek,
simple and easy to understand with the pictorial representation
Happy Morning Marek,
Below text is from CISM Review Manual where AIW (Acceptable interruption window) was mentioned. Is AIW same as MTD? Need your help to clarify!
Regards,
Santha Kumar N.
4.10.6 BASIS FOR RECOVERY SITE SELECTIONS
The type of site selected for a response and recovery strategy should be based on the following considerations:
•AIW—The total time that the organization can wait from the point of failure to the restoration of critical services/applications. After this time, the cumulative losses caused by the interruption may threaten the existence of the organization.
Hi Santha,
Well, judging from the text you posted I would assume that it is indeed the same.
Cheers!
Thanks for this.. Where does AIW fit into the picture ? Is it the same as MTD ??
Hi,
Well, as already mentioned by the poster above. I would say yes but I am not 100% sure.
Cheers!
Nice explanation. I was struggling to understand the difference between these. Thank you
Hi,
Thank you, nice explanation, simple and easy
Cheers! 🙂
Amazing simplified graphic, really clarified things. Acronym overload makes me go cross eyed so thank you!
Cheers!
Fabulous discussion, but a couple of nuanced corrections: First, RPO is more or less correct, but it should be stressed that this is a metric that looks backward in time from the disaster. That said, the arrow should just start at the disaster line (Stage 2) and point to the left. Stressing the notion of “backward-looking” and the arrow pointing to the left help communicate this point. Second, your definition of MTD is wrong. Period. Full stop. Whereas all of these definitions are often confused and therefore there is no definitive reference point, the most widely accepted definition of MTD is that it is the recovery metric for a business process, not just for IT assets. Look up the top Google hits on this term and you will see. The definition in the drawing above does not take into account all other factors required to get a business process recovered, including relocating staff, activating alternate workspace, and all the internal and external third party dependencies that are required: vendors, suppliers, business partners, regulators, etc. Some of this stuff may happen before, after, or during RTO, but it is all cumulatively part of MTD. Personally, I’d include all the stuff you put into your MTD definition as part of the RTO metric…and so would you, judging by your own definition of MTD: “When all SYSTEMS affected by the disaster ARE verified and/or RECOVERED.” Caps added by me for emphasis. The tasks that you mention in MTD are part of the recovery of systems and should be part of RTO. Peace.
Hi,
First off all, thanks for taking your time to contribute to this discussion.
Regarding RPO, good point. I’ll update the blog on the backward in time arrow. Btw, the arrows are just to indicate the boundaries not a direction of time.
Regarding MTD, as described below, this post is dedicated for an IT department. I understand that it is not just for IT assets but I don’t agree with you that the definition is incorrect.
On the other hand, this article is almost 5 years old. I should probably review and update it.
Cheers!
All of these are metrics used in SLA’s\SLO’s which are typically measured over periods, often times over the period of a month. Is there a widely used acronym that describes the total allowable downtime within a period of time? For instance, if you have repeated outages within a month and each outage is fully recovered within the RTO, RPO, MTD but the total amount of downtime is unacceptable, what acronym is used to describe the maximum tolerable downtime collectively in a period or the maximum number of allowable outages in a period of time?
To be hones Troy, I have no idea. Maybe someone from other readers knows…
I do no believe there is an acronym for a cumulative downtime over a certain amount of days/month/year. I can only think of SLA which is expressed in % over a one-year period.
Very nice explanation, Thanks
Thanks Mareck..Explained well with pictorial representation. helped me to the understand the concept easily
Even in 2020 this post is still used….thanks for your work, great job 🙂
well done. Lovely explanation. Refreshing discussions where I have gleaned a lot of information . Thanks to all of you once again especially the author of the post
Hi Marek, Great article. Would you be willing to grant me permission to reproduce your diagram in a book I’m writing?
Very much appreciated this. Thank-you.
RTO would be higher then RPO or what should be the right answer ? bit confused? . Also request to pls share any more article on BIA and BCP metric with sample